Incomplete and messy CRM data is the most common root cause behind failed pipeline audits. When over 40% of your customer database consists of duplicates, out-of-business records, or accounts with incorrect classification, every downstream process breaks: segmentation, routing, forecasting, and marketing automation all operate on a foundation that does not reflect reality.
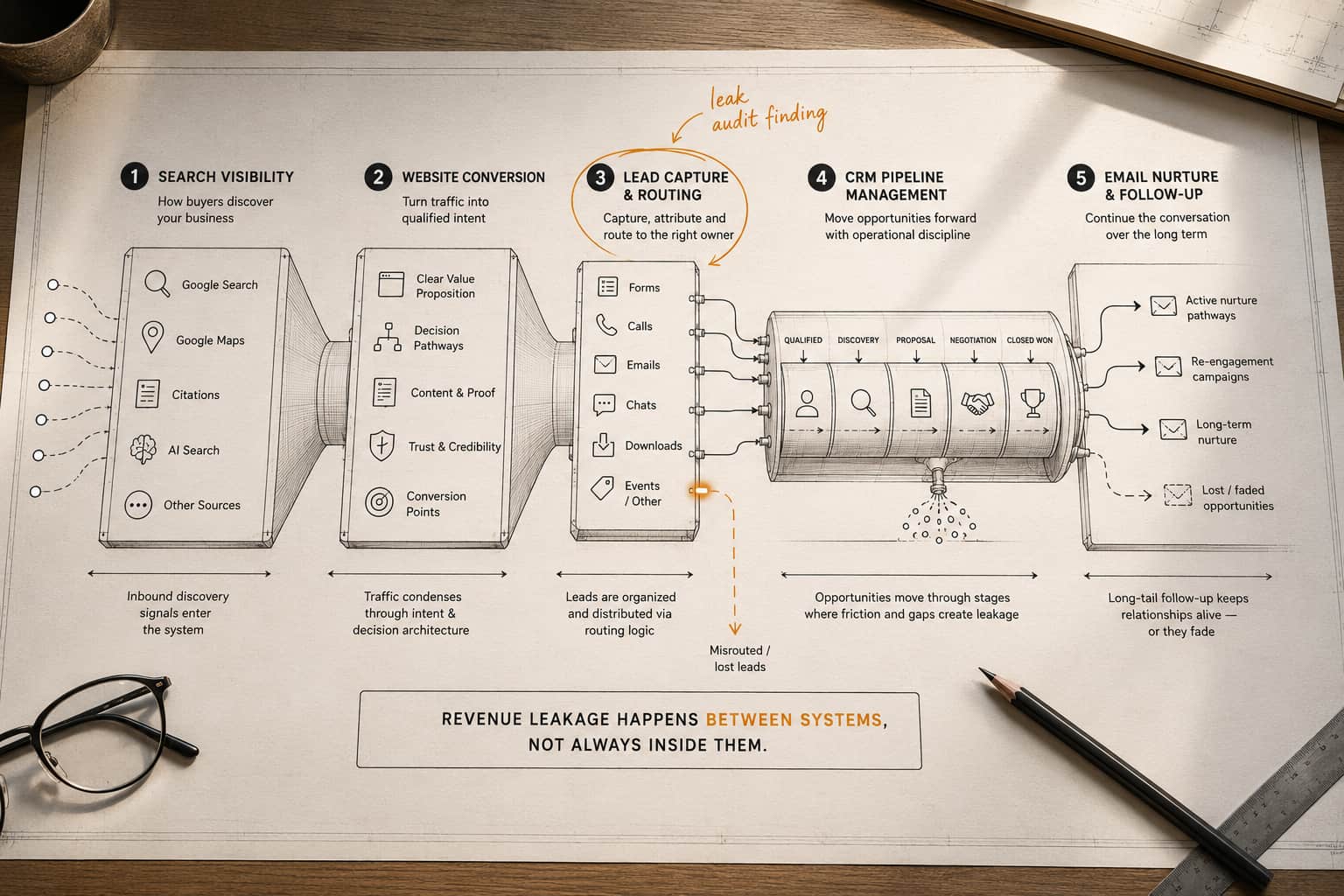
This article is a companion piece to the CRM pipeline audit framework published earlier this week. That audit identifies where your pipeline is leaking. This one explains why the leaks keep coming back, and how to fix the underlying data problem so your CRM actually works as a system.
How bad is CRM data quality in a typical B2B company?
Worse than most leadership teams realize, because the symptoms are indirect. Nobody gets an alert that says "40% of your records are unreliable." Instead, the symptoms look like pipeline problems: reps say leads are low quality, marketing says leads are not being followed up, and management cannot get a straight answer on forecast accuracy.
At a large equipment dealer group I worked with, we ran a full database audit as part of a broader sales operations overhaul. The findings were representative of what I see across B2B companies in asset-heavy industries.
- Over 40% of customer records were duplicates, out-of-territory entries, or companies that had closed
- Roughly 20% had incorrect division assignments or classification, meaning leads were routed to the wrong team
- Under half of all customer records had any contact details attached, not even an email address
- Of those contacts that did exist, only about 60% had both a phone number and email, the bare minimum for outreach
- Over 60% of the total customer base was completely unassigned to any sales rep or marketing program
That last number is the one that hit hardest. Over 60% of known customers had no one responsible for them. They existed in the CRM but were invisible to the commercial team. Not being prospected, not receiving marketing communications, not being assigned for account management. They were simply sitting in a database, aging.
Why does bad data keep coming back after you clean it?
Most companies that recognize a CRM data problem try to solve it with a cleanup project: deduplicate records, update contact info, fix classifications. Six months later, the database is degraded again. The reason is that cleanup treats the symptom, not the cause.
Data quality degrades because there are no input standards. New records enter the CRM without required fields. Reps create accounts without checking for duplicates. Classification codes are optional, so they get skipped. Assignment rules are informal, so accounts accumulate in an unassigned pool that nobody monitors.
The fix is not a cleanup project. It is a permanent change to how data enters the system.
- Define mandatory fields for every new account: industry code, contact information (email and phone), classification, and assignment. If these fields are empty, the record cannot be saved.
- Assign a data gatekeeper function. This does not have to be a dedicated person. It can be a department (credit, operations, or data team) that reviews and approves new account creation.
- Establish an assignment rule: zero unassigned accounts. Every customer must belong to a sales rep, a marketing program, or a defined nurture segment. If a rep leaves, their accounts must be redistributed within a set timeframe.
- Validate contact data on a schedule. Email addresses decay at roughly 25% per year in B2B. Phone numbers change. Run validation quarterly, not annually.
What does unassigned customer data actually cost you?
When over 60% of your customer database is unassigned, you are not just missing cross-sell opportunities. You are operating with a fundamentally incomplete view of your market coverage.
At the dealer group, we mapped CRM data against actual transaction records from the previous ten years. The result: the CRM recognized only about a third of actual customers. The rest had bought equipment, parts, or service but existed only in the financial system, not in the sales pipeline. Nobody was responsible for retaining those relationships.
When we cross-referenced unassigned accounts against transaction data, we found hundreds of machines that had been sold to customers who were not assigned to any rep. These customers were receiving no proactive outreach for parts, service, or replacement cycles. The revenue sitting in that unassigned pool was significant.
The fix was a structured assignment model with four tiers: field sales reps for high-value accounts, inside sales for mid-tier, business development reps for prospects, and marketing automation for the long tail. The goal was simple: 100% coverage. Every known customer assigned to someone or something.
How do you audit your CRM data quality in under two hours?
If you ran the full pipeline audit from the Monday article, you already have half the picture. This data quality check adds the other half. Block two hours and run these four reports.
- Duplicate rate: Export your account list and sort by company name and address. Flag exact and near-matches. In most CRMs, this is a built-in report or a low-cost third-party tool. Anything above 10% is a problem. Above 25% is a crisis.
- Contact completeness: Count accounts with zero contacts, contacts with no email, and contacts with no phone. If under half of your accounts have usable contact details, your email campaigns and phone outreach are running on a fraction of your actual market.
- Assignment coverage: Pull the number of accounts with no assigned owner. Break it down by customer segment or value tier. Unassigned accounts in your top 20% of revenue are the highest-priority fix.
- Classification accuracy: Sample 50 accounts at random. Check whether their industry code, division assignment, and customer type are correct. If more than 20% are wrong, your segmentation and routing logic is built on bad data.
These four reports give you a data quality score. They also give you the business case for investing in CRM hygiene, because you can attach revenue estimates to the unassigned and unreachable accounts.
Key takeaways
- Most B2B CRMs contain over 40% low-quality records: duplicates, out-of-business entries, or misclassified accounts. This is not a data problem. It is a revenue problem, because every downstream process depends on this foundation.
- One-time cleanup projects fail because they treat the symptom. Permanent input standards, mandatory fields, a gatekeeper function, and a zero-unassigned-accounts rule are what prevent data from degrading again.
- Unassigned accounts are the most expensive gap. At one dealer group, over 60% of known customers had no rep, no marketing program, and no automated nurture. The revenue sitting in that pool was substantial.
- A CRM data quality audit takes two hours and four reports: duplicate rate, contact completeness, assignment coverage, and classification accuracy. Run it immediately after a pipeline audit to understand why the leaks you found keep recurring.
Synapse Edge is a B2B revenue infrastructure consultancy, not a software vendor. CRM data quality is one of the first things we assess in every engagement because it determines whether any sales operations improvement will hold. The process works regardless of your CRM platform.
CRM data quality is the hidden foundation beneath every pipeline metric. When over 40% of records are duplicates or misclassified, and over 60% of accounts are unassigned, segmentation, routing, forecasting, and marketing automation all fail quietly. Fixing CRM data requires permanent input standards and assignment rules, not one-time cleanup projects. A two-hour audit covering duplicate rate, contact completeness, assignment coverage, and classification accuracy will reveal the true state of your database and the revenue it is costing you.
Want to find out what your CRM data is costing you? Use our free diagnostic tools to run both the pipeline and data quality audits together.