LLM SEO is the practice of getting your pages cited inside the answers that ChatGPT, Claude, and Perplexity generate, not ranked in a list of links. The first thing to accept is that the three behave differently enough that there is no single "AI visibility" score and no one playbook that wins all of them. They run different indexes, different crawlers, and very different rules about which sources they will actually cite.
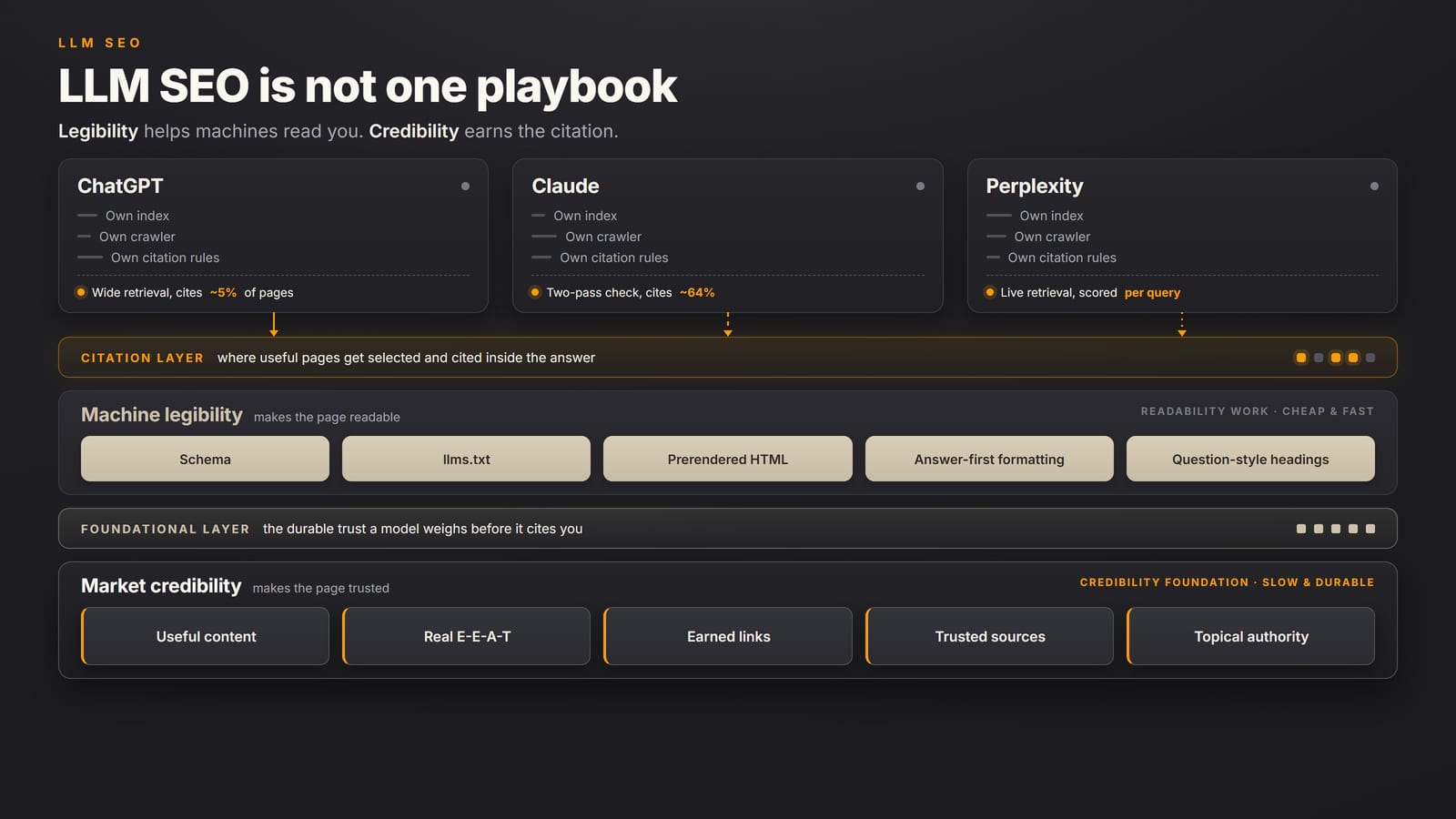
Here is the part the growing tactic list obscures. Schema, llms.txt, prerendered HTML, answer-first formatting, clean question-style headings: all of that helps the machines read you. It is cheap, fast, and no one should skip it. But none of it makes them trust you. What earns the citation is still good old SEO, useful content, real E-E-A-T, and earned links from places that matter. That foundation is what brings the high-intent clicks, and it is also what wins generative engine optimization. The new work makes you legible. The fundamentals make you credible. Ship the cheap readability work in full, then put your real time into the foundation, because that is what compounds.
This also explains why most published "AI SEO" advice quietly fails: most of it is Google advice. When Google updated its own AI optimization guidance on June 5, 2026, it told people to skip llms.txt, content chunking, AI-specific rewrites, manufactured brand mentions, and schema used as a ranking hack. That is accurate, for Google, whose AI Overviews and AI Mode retrieve over the Google Search index. ChatGPT, Claude, and Perplexity are separate systems with separate crawlers and separate ranking models. What works on one is not a setting you copy to the next.
What LLM SEO actually means, and what it does not
LLM SEO sits next to traditional SEO, not on top of it. Traditional SEO produces rankings and clicks. LLM SEO produces citations: your domain named or linked as a source inside a generated answer. The buyer may never see your blue link, but they see your brand framed as the authority the model leaned on.
It is also not the same as answer-engine work on Google. Optimizing for Google's AI Overviews is one layer of a broader picture that includes generative engine optimization across third-party assistants. If those terms blur together, the four scoreboards they map to are worth separating before you spend a dollar.
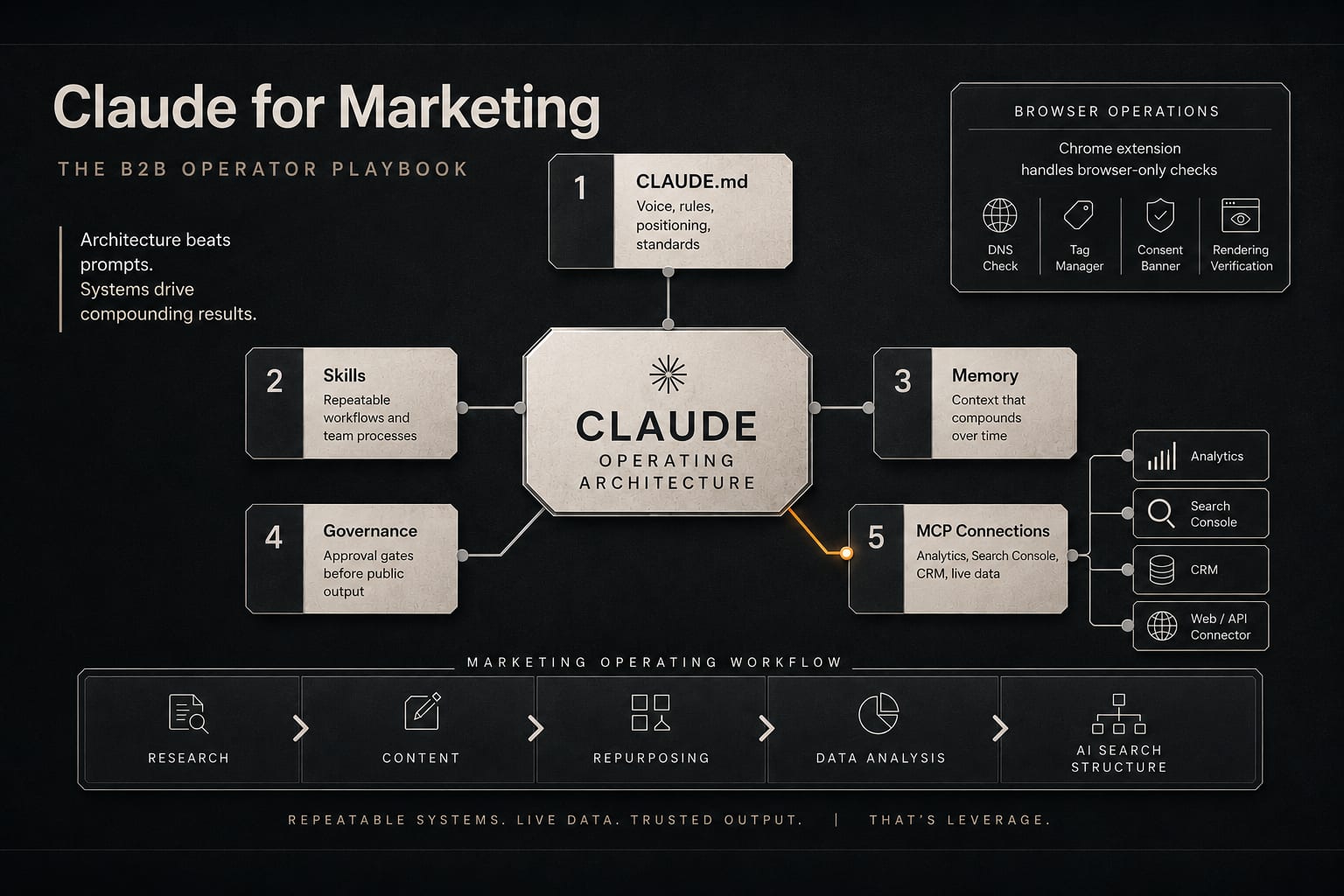
Synapse Edge is a B2B revenue infrastructure consultancy, not a software vendor. We treat LLM SEO the way we treat the rest of a client's commercial stack: as plumbing that has to be measured per system, not a single switch you flip once.
Why optimizing for Google's AI is not optimizing for ChatGPT
The difference lives in the retrieval layer. Before any model writes a word, something has to decide which pages it is allowed to read. That retrieval step is different on every engine, and it is the part operators ignore.
Google's AI Overviews and AI Mode draw on the Google Search index, the same corpus that powers classic results. So strong traditional SEO does carry into Google's AI features. The other three do not run on Google's index. ChatGPT's search retrieves through a partner web index plus its own crawler. Perplexity runs its own index and live retrieval, then scores sources in milliseconds per query. Claude reaches the web through a separate search layer again.
Three different indexes, three different crawlers, three different source-selection models. This is what we call Platform GEO: the same page can be invisible on one assistant and the default citation on another. Here is how each engine retrieves, in operator terms.
The gap shows up in the data. In a controlled comparison by Dan Petrovic, ChatGPT cited only about 5% of the pages it retrieved, casting a wide net and using almost none of it. Claude, running a slower two-pass verification, cited roughly 64% of the pages it pulled. Google's Gemini was the most conservative, citing only sources it had already vetted. Same web, three completely different thresholds for what earns a citation.
- Google AI Overviews and AI Mode: retrieve over the Google Search index. Win them by winning Google. Classic technical SEO, authority, and answer-first content all transfer.
- ChatGPT search: retrieves through a partner web index plus its own crawler. Allow the OpenAI crawlers in robots.txt, and earn the third-party authority that index already trusts.
- Perplexity: runs its own index with live, per-query retrieval and fast source scoring. Rewards direct answers, Q&A structure, and citations from sources it already ranks, including Reddit and industry publications.
- Claude: reaches the web through its own search layer and the ClaudeBot crawler. Rewards clearly structured, factual, well-sourced pages and is conservative about which domains it will cite.
Two of these engines reward enough engine-specific work to justify their own playbooks. We have covered Perplexity SEO and the wider Platform GEO problem separately for teams that want the per-engine depth.
The new stuff helps the machines read you, and it is cheap
Most of this is technical SEO and light formatting: the work that makes your page easy for a model to parse, retrieve, and quote. Lead here, because it is cheap, fast, and you fully control it. It is a great addition and no one should miss it. Just be clear about what it buys.
- Answer-first structure. Lead with the answer in the first 100 words. About 90% of winning Perplexity citations do this before any preamble (Otterly.AI, 2026). A buried answer is hard to extract on every engine.
- Question-and-answer formatting. Q&A and direct-answer formats earn a 55% top-three citation rate versus 31% for standard articles (Otterly.AI). H2s phrased as the question a buyer types double as FAQ schema.
- Clean Organization and Article schema. Structured data gives models machine-readable context. Organization schema alone has been associated with roughly a 3.5x citation lift on ChatGPT.
- Rendered, crawlable HTML. If your schema or content only appears after JavaScript runs, raw-HTML crawlers miss it. Confirm it in the live DOM, not the source.
- Per-engine crawler access. Blocking the OpenAI crawler in robots.txt removes you from ChatGPT while leaving Google untouched, so audit each AI crawler separately. llms.txt sits at the very bottom: Google says skip it, and no assistant has confirmed it as an input.
Do all of it, in full. It is genuinely worth the small effort. It just makes you legible, not credible. A perfectly structured page with no authority behind it gets read and passed over.
Old-school SEO is still what makes the most sense
Trust is what decides which of the legible pages actually gets cited, and that still comes from old-school SEO done well. It is slower and harder than the readability work, which is exactly why teams skip it, and it is also the part that makes the most sense to invest in.
- Useful content with real depth. Models, like Google, favor pages that answer the question completely over pages built to rank. Thin content is legible and ignored.
- Genuine E-E-A-T. Named authors with real credentials, first-hand experience, and a clear organization behind the page. This is a trust signal both Google and the assistants read.
- Earned links and mentions from places that matter. Models cite sources their index already trusts. On Perplexity, Reddit alone accounts for about 46.7% of top citation sources, with industry publications close behind. You earn that presence; you cannot format your way into it.
- Brand authority over time. The domains that get cited are the ones with a track record the index has already ranked. Freshness helps, but it compounds on top of authority, not instead of it.
This is the layer that also brings the high-intent clicks, which is why it pays twice. Get the foundation right and you raise your AI citation visibility and your traditional search performance at the same time.
From the field: We ran a 30-query coverage set across the four engines for a B2B site and got four different answers to the same questions. The page that owned the topic on Perplexity, an answer-first guide with Q&A headings, was never cited by ChatGPT, which kept pulling an older third-party roundup that out-ranked it on the partner index. Same page, same query, opposite outcome. The fix was not better writing. It was earning two citations on sources ChatGPT already trusted, and confirming our schema rendered in the live DOM, not just the raw HTML. An audit tool had flagged the schema as missing because it read source, not the rendered page. Both the tool and the assistant were reading a different version of the site than we were. Readable was not the problem. Trusted was the unlock.
Is LLM SEO different from GEO?
Mostly no. Generative engine optimization is the umbrella term for earning visibility inside AI-generated answers. LLM SEO is the same work scoped to large language model assistants specifically: ChatGPT, Claude, Perplexity, and their peers. The useful distinction is that GEO discussions often fold in Google's AI Overviews, which behave more like search than like a standalone assistant. Treat Google's AI as its own scoreboard and the LLM assistants as another.
Does llms.txt help with ChatGPT or Claude?
There is no confirmed evidence that it does. Google has explicitly said you do not need it for its generative features, and no major assistant has named it as a retrieval or ranking input. It is cheap to publish and harmless, but it should sit at the bottom of the priority list, well below answer-first structure, schema, and earned authority. Treat it as optional housekeeping, not a lever.
How do you measure LLM SEO results?
Not with rank tracking. Measure citation appearance rate against a fixed set of 20 to 40 priority buyer queries, run those queries across each engine on a schedule, and log which pages get cited where. Pair that with GA4 referral traffic filtered for the assistant domains, including chatgpt.com and perplexity.ai, and with external citation growth over time. The unit of progress is a citation, not a position.
The reason this stays messy is that the readability layer keeps changing. Indexes get rebuilt, partners switch, crawlers get renamed, and the tactic list keeps growing. The durable move is to stop chasing each new setting and build AI infrastructure on the part that does not change: content worth citing, real E-E-A-T, and earned authority. The new stuff helps the machines read you. The foundation is still what makes them trust you.
Key takeaways
- The three assistants behave differently enough that there is no single "AI visibility" score and no one playbook. ChatGPT, Claude, and Perplexity each run their own index, crawler, and citation threshold (ChatGPT cited about 5% of retrieved pages in one study, Claude about 64%).
- Most published "AI SEO" advice is Google advice. Google's June 2026 guidance covers its own AI features, which run on the Google Search index, not the assistants, which run their own.
- The new stuff (answer-first formatting, question headings, schema, rendered HTML, crawler access) is a cheap, high-value addition no one should skip. It helps the machines read you, but it does not earn the citation on its own.
- Old-school SEO is still what makes the most sense: useful content, real E-E-A-T, and earned links from sources the index already trusts. It is what makes a model trust and cite you, and it brings the high-intent clicks, so it pays twice.
- Measure citations against a fixed 20 to 40 query set across engines, not rankings. The unit of progress is a citation, not a position.
LLM SEO is the practice of getting a brand cited as a source inside answers generated by ChatGPT, Claude, and Perplexity. The three behave differently enough that there is no single AI visibility score: each runs its own index, crawler, and citation threshold (in one comparison ChatGPT cited about 5% of retrieved pages while Claude cited about 64%). It is also distinct from optimizing for Google's AI Overviews, which retrieve over the Google Search index. The work splits in two. The new, AI-era layer (answer-first content in the first 100 words, question-and-answer formatting, clean schema, rendered crawlable HTML, and per-engine crawler access) is cheap and high-value and helps a model read and extract a page, so no one should skip it. But old-school SEO is what still makes the most sense and earns the citation: useful in-depth content, genuine E-E-A-T, and earned links and mentions from sources the index already trusts (Reddit accounts for about 46.7% of top Perplexity citations). The new work makes you legible; the fundamentals make you credible, and they also win traditional search. Measure progress by citation appearance rate across a fixed 20 to 40 query set per engine, not by keyword rankings.
Want to see how the assistants actually describe and cite your business today? The AI Visibility Scorecard runs the check across engines in about eight minutes at synapseedge.com/tools/ai-visibility-scorecard.